我原本昨天寫好發完的...結果今天被通知段賽...不知道甚麼問題
昨天我們把神經元堆疊成多層,終於組出了一個能處理更複雜問題的「冒險隊伍」。但是光有隊伍還不夠,訓練過程中會遇到數值不穩、學習卡住的狀況。今天我們就要學習兩個超實用的技巧 —— 小批次訓練 和 正規化,幫模型維持戰鬥狀態!
一、為什麼需要這些技巧?
在訓練深層神經網路時,常見的兩大瓶頸是梯度爆炸與梯度消失:前者指梯度在層與層之間傳遞時不斷放大,最終造成數值失控與權重飆升,使模型無法繼續有效訓練;後者則是梯度一路衰減直至接近零,導致網路幾乎學不到東西。這兩種狀況就像一支冒險隊伍打怪卻缺乏補給:不是血量瞬間暴增失控,就是魔力耗盡放不出招,結果同樣無法順利推進。
二、小批次訓練(Mini-Batch Training)
在更新權重時,最常見的梯度下降法有三種:
| 訓練方式 | 優點 | 缺點 |
|---|---|---|
| 整批訓練 | 訓練過程穩定,結果準確 | 訓練過程過慢,對記憶體消耗大 |
| 單筆訓練 | 訓練過程較快,每次更新權重時使用一筆資料 | 結果較不穩定,訓練過程有較大噪音 |
| 小批次訓練 | 結合效率與穩定,處理速度較快,內存消耗低 | 訓練過程中可能會有小的波動,但整體比較穩定 |
小批次訓練 是當前最主流的訓練方式,它每次使用一小部分的資料來更新模型權重(例如每次處理 32 或 64 筆資料)。這樣的方式不僅能夠提升訓練效率,還能穩定訓練過程,避免了單筆訓練的極端波動。
三、正規化(Normalization)
即使使用小批次訓練,數值的不穩定性仍然可能存在,特別是在網路層數過深的情況下。這時候就需要正規化技術來幫助穩定模型的學習過程。
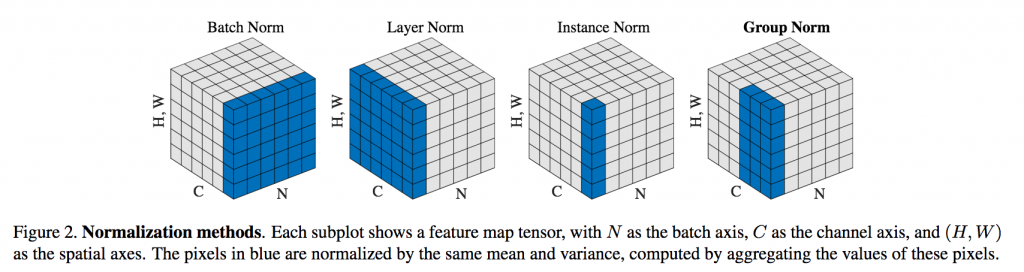
Batch Normalization (BatchNorm)
BatchNorm 是一種對每個 小批次的輸入 進行標準化的方法。它對每一小批資料進行標準化,使得每一層的輸入均值為 0,方差為 1。這樣可以減少數據的波動性,讓模型訓練過程更穩定。
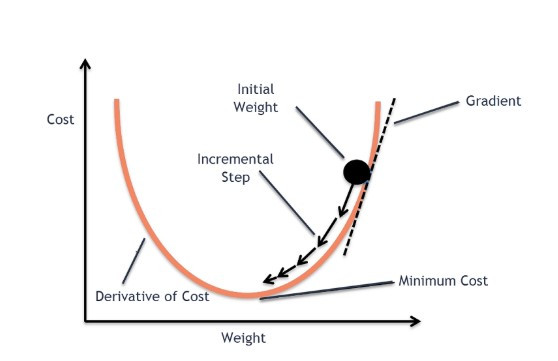
這是Batch Normalization 的運作流程。BN 會計算小批次的均值 ($\mu$) 和方差 ($\sigma^2$),將數據標準化(使均值為 0、方差為 1)後,再透過兩個可學習參數 $\gamma$(縮放)和 $\beta$(平移)進行微調,確保數據分佈在最適合下一層激活函數的區間。
BatchNorm 的好處:
1.加速收斂: 因為數據分佈更穩定,網路可以更快速地收斂。
2.減少過擬合: 有助於在訓練中引入一些噪音,避免模型對訓練資料過於擬合。(例如,它也是 ResNet 架構能訓練數十層的關鍵技術之一。)
Layer Normalization (LayerNorm)
LayerNorm 是對 每一層的神經元 進行標準化的方法。與 BatchNorm 不同,LayerNorm 是對每一層的輸入進行標準化,這樣每一層的輸入將有相同的分佈。這種方法尤其適用於序列模型(如 RNN 或 Transformer),因為它能夠在每一層內進行穩定化,並且不依賴於小批次的大小。
LayerNorm 的好處:
1.在序列模型中,LayerNorm 能夠有效地幫助模型處理變長的輸入序列。
2.能夠使每一層的數據分佈更加穩定,避免數據偏移造成的訓練困難。
小批次訓練與正規化技術的結合能夠有效解決梯度爆炸與梯度消失問題,並且提升神經網路訓練的穩定性和效率。如果這些技術應用得當,它們不僅能夠提高訓練的速度,還能減少過擬合,保證模型在測試數據上的表現。

